A machine learning approach to predict sediment accumulation at the seafloor
Supervisors:
- Prof. Dr. Klaus Wallmann, GEOMAR Helmholtz Centre for Ocean Research Kiel, Marine Biogeochemistry, kwallmann@geomar.de
- Prof. Dr. Malte Braack, University of Kiel, Department of Mathematics, braack@math.uni-kiel.de
Location: Kiel
Disciplines: physical oceanography, numerical mathematics, computer science
Keywords: sediments, machine learning, data approximation
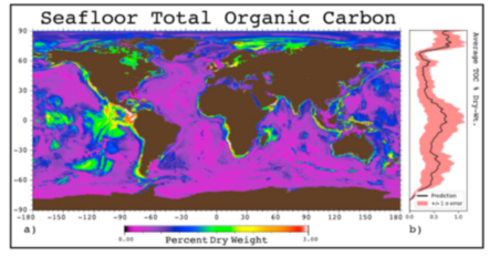
Objective: Despite the importance of seafloor sediments as a major global sink of carbon direct observation on the mass accumulation rate (MAR) of sediments are sparse, and large areas of the seafloor remain virtually unexplored. As a result, the existing data sets are inadequate to quantify the burial and removal of carbon and other seawater constituents at the seabed at global scale. Machine learning techniques employing e.g. the k-nearest neighbors algorithm have provided estimations of sediment properties (e. g. porosity, carbon content, lithology, biomass distribution) where little to no data exist (see Fig.). These machine learning algorithms are essentially a formalization of the intuitive notion that if two locations on the seafloor are similar in terms of known properties (predictors) then they are also similar in a way that we have not observed (Lee et al., 2019). More than 600 global predictor maps with a spatial resolution of 5 x 5 arc-minutes have been recently compiled (https://doi.org/10.5281/zenodo.1471638). They include key seafloor properties (bathymetry, bottom currents, distance to coasts and river mouths, etc.) that collectively regulate the distribution and accumulation of sediments at the seafloor. Moreover, a large but sparse data set of mass accumulation rates (>3700 MAR data) has been compiled at GEOMAR (https://portal.geomar.de/group/sfb754/sedimentation-database) that can be used for this project and will be continuously updated over the coming years.
Aim: In the project, we will develop and apply machine learning techniques to derive global maps of sediment accumulation at the seafloor using available predictor maps and our sparse data set on sediment accumulation rates. Different algorithms will be tested and adapted to provide a methodology that can be used to derive sediment properties were no data exist. An usual assumption in approximation theory, e.g. by use of radial basis functions, is that the function to be approximated is smooth. This is certainly not valid for the sediment properties. Therefore, standard machine learning approaches have to be adapted, e.g. by incorporation of expert knowledge. As an end product we expect the derivation of reliable global maps of MAR and further sediment properties.
References:
- Lee, T., Wood, W.T. and Phrampus, B.J. (2019) A Machine Learning (kNN) Approach to Predicting Global Seafloor Total Organic Carbon. Global Biochemical Cycles 33.
- Iske, A. (2018) Approximation Theory and Algorithms for Data Analysis. Texts in Applied Mathematics 68, Springer.