Deep neural networks for the prediction of sediment accumulation at the seafloor
Doctoral researcher:
Naveen Kumar Parameswaran, GEOMAR Helmholtz Centre for Ocean Research Kiel, nparameswaran@geomar.de
Supervisors:
- Prof. Dr. Klaus Wallmann, GEOMAR Helmholtz Centre for Ocean Research Kiel, Marine Biogeochemistry, kwallmann@geomar.de
- Prof. Dr. Malte Braack, University of Kiel, Department of Mathematics, braack@math.uni-kiel.de
Location: Kiel
Disciplines:
Keywords: marine carbon cycle, ocean sediments, machine learning, uncertainty quantification
Motivation:
Together, the creatures of the oceans and the physical features of their habitat
play a significant role in sequestering carbon and taking it out of the atmosphere. Through the biological processes of photosynthesis, predation, decomposition, and the physical movements of the currents, the oceans take in more carbon than they release. With sediment accumulation in the deep seafloor, carbon gets stored for a long time, making oceans big carbon sinks, and protecting our planet from the devastating effects of climate change.
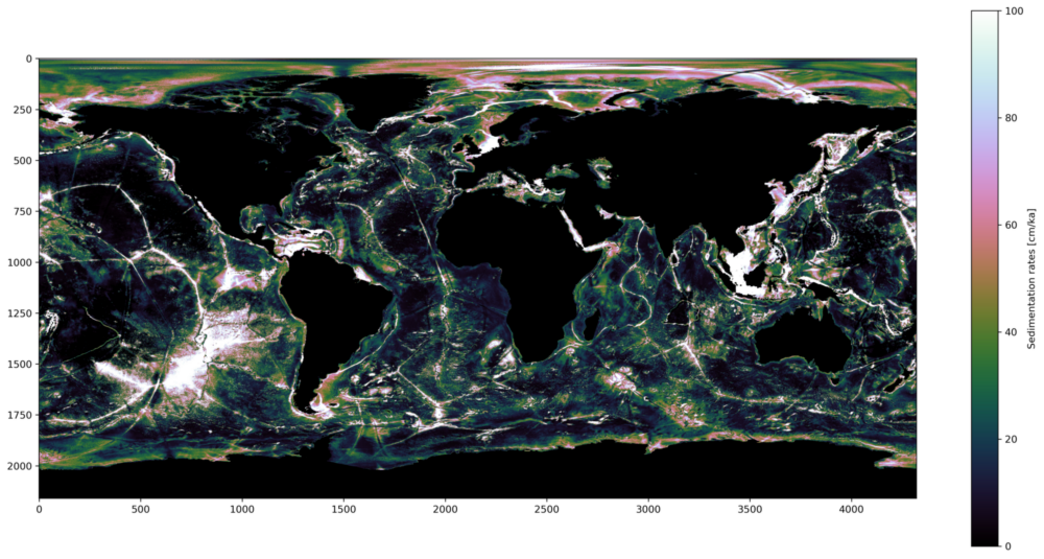
Despite the significance of seafloor sediments as a major global carbon sink, direct observations on the mass accumulation rates(MAR) of sediments are sparse. The existing sparse data set is inadequate to quantify the change in the
composition of carbon and other constituents at the seabed on a global scale. Machine learning techniques such as the k-nearest neighbor's algorithm have provided predictions of sediment accumulation rates (Mitchell et al., 2021, Restreppo et al., 2020), by correlating known features (predictors) such as bathymetry, bottom currents, distance to coasts and river mouths, etc.
Aim:
In my current work, global maps of the sediment accumulation rates at the seafloor are predicted using the known feature maps and the sparse dataset of sediment accumulation rates using multi-layer perceptrons(supervised models). Despite a good model accuracy, the predictions are not reliable, according to expert knowledge. Some of the main problems are the low availability of labelled data, uneven distribution(both spatially and mathematically) of sediment accumulation rates, and low knowledge about feature relevance. To understand the unreliability of predictions and the
impact of the problems, model uncertainty is being studied using three approaches, namely using a bayesian neural network, using a Monte Carlo dropout and considering the problem as a classification problem. Also, feature relevance will be studied using Feature pruning and Automatic relevance determination.
The unreliable predictions by a supervised multi-layer perceptron using only the sparsely available labelled dataset necessitate the incorporation of another approach. Semi-supervised learning approaches have shown great efficiency
in natural language processing and computer vision tasks, where very few labelled data is available, thus making the best use of unlabelled data samples. An semi-supervised approach called as the SimCLRv2(Chen et al., 2020) will be implemented to predict sediment accumulation rates in the seafloor.
References
- Giancarlo A. Restreppo, Warren T. Wood Benjamin J. Phrampus (2020): “Oceanic sediment accumulation rates predicted via machine learning algorithm: towards sediment characterization on a global scale”. In: Geo-Marine Letters 40, pp. 755–763.
- P.J.Mitchell M.A.Spence, J.Aldridge A.T.Kotilainen and M.Diesing (2021): “Sedimentation rates in the Baltic Sea: A machine learning approach”. In: Continental Shelf research 214, p. 104325.
- Ting Chen, Simon Kornblith, Mohammad Norouzi, and Geoffrey Hinton: Big Self-Supervised Models are Strong Semi-Supervised Learners. arXiv preprint arXiv:2006.10029, 2020